
AWS Athena è uno strumento molto potente ma, per poterlo sfruttare al meglio, sono necessari alcuni accorgimenti.
Immaginiamo di essere un’azienda sul mercato da qualche anno, che gestisce, quotidianamente, campagne pubblicitarie su diverse piattaforme, come ad esempio Google Ads e Meta, per commercializzare i propri prodotti.
I nostri team di marketing avranno la necessità di monitorare l’andamento delle varie campagne, quali sono i prodotti che stanno vendendo di piú e come questi cambiano nel tempo.
Per poter avere dati strutturati e, quindi, gestibili, il team tecnico, nel tempo, avrà forse pensato di organizzarli per sorgente, anno e mese, in modo da poter fornire strumenti di analisi specifici ed avere, in generale, tabelle più piccole su cui lavorare.
Se, da un lato, questo è, senz’altro, un passaggio utile, risulta piuttosto difficile gestire le analisi multi-sorgente, su archi temporali lunghi e che vadano ad incrociare i dati di revenue.
Molto probabilmente, avremmo a che fare con decine di tabelle sul database. Per questo motivo, abbiamo necessariamente bisogno di un tool in grado di analizzare grandi quantità di dati in poco tempo.
AWS Athena: le 3 fasi del processo di migrazione dei dati
Vediamo, ora, con maggior grado di dettaglio, come si può passare da un database relazionale, come MySQL, ad AWS Athena.
Le fasi del processo sono, fondamentalmente, tre:
- Pacchettizzazione dei dati
- Salvataggio dei dati su Amazon S3
- Creazione della tabella AWS Athena
Pacchettizzazione dei dati
AWS Athena lavora con dati tabellari. Questo è uno dei motivi da cui dipende la sua significativa velocità. A condizione, però, che i dati sul nostro database relazionale siano organizzati in questo modo:
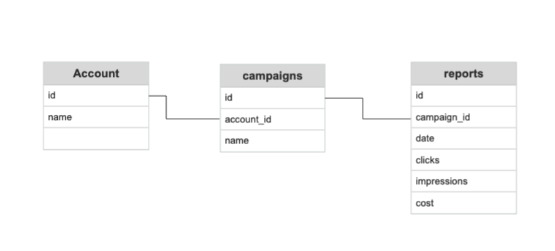
Il relativo formato tabellare, ad esempio, CSV, dovrà essere il seguente:

Salvataggio dei dati su Amazon S3
Dopo aver organizzato i dati nel formato tabellare richiesto, dobbiamo caricare il file su un bucket S3.
Ad esempio, potremmo decidere di avere un file per ogni giorno del mese. In questo caso, il nostro storage avrà una struttura del genere:
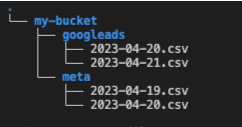
Creazione della tabella AWS Athena
AWS Athena è un sistema di query, che segue le regole di SQL Standard. Stiamo parlando, quindi, di logiche a cui siamo abituati. Si possono costruire database, tabelle e viste.
Partendo dai dati caricati sul nostro storage Amazon S3, possiamo creare una tabella che sia in grado di leggerli, come segue:
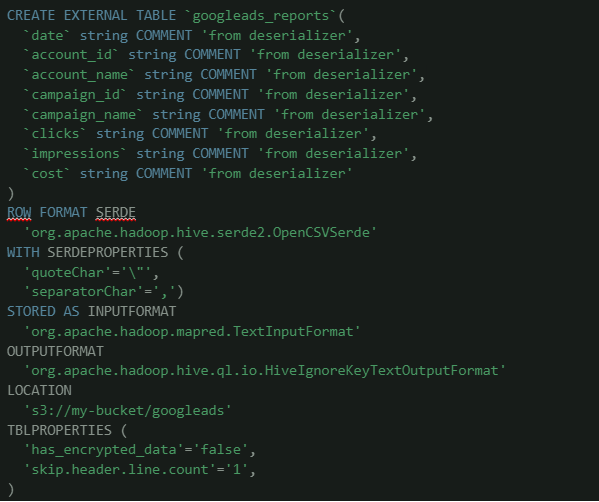
In particolare, è importante soffermarsi su due aspetti, spesso ignorati sulle guide (anche quelle ufficiali), ma estremamente importanti. Non ignorarli, potrebbe, addirittura, salvarvi la vita!
- Athena legge i file CSV in modo posizionale, quindi, se nel corso del tempo, dovete aggiungere nuove colonne, è importante farlo sempre alla fine, altrimenti avrete i dati vecchi mischiati ed in posizioni errate;
- Athena gestisce molte tipologie di dati, ma, come avrete notato, nel precedente esempio, abbiamo utilizzato il formato ‘string’; questo perché Athena è molto rigida nel casting delle varie tipologie di dati. Quindi, se un certo valore non si adatta al formato dichiarato, l’intera query fallisce.
Il modo più efficace che abbiamo trovato in Move Forward per risolvere il problema è stato quello di dichiarare i campi sempre string e di utilizzare, poi, i costrutti TRY/CAST in fase di query, per adattare il tipo di dato desiderato.

Vuoi sapere qual è il miglior modo di creare una tabella su AWS Athena? Vuoi migrare agevolmente e senza preoccupazioni i tuoi dati su AWS Athena? Contattaci per maggiori informazioni!
Siamo anche su Facebook!
Vieni a trovarci, cliccando QUI!




