
Dopo aver capito come si preparano i dati e, soprattutto, come sfruttare, al meglio, lo storage di AWS S3 per creare tabelle in AWS Athena, non ci resta che ottimizzare il tutto!
- Cosa sono e a cosa servono le partizioni
- Perché le partizioni sono importanti in AWS Athena
- Come organizzare i dati su AWS S3 per gestire automaticamente le partizioni di AWS Athena
- Performance Benchmark: Partizione vs Non Partizione
Cosa sono e a cosa servono le partizioni
In SQL, le partizioni sono funzionalità che consentono di suddividere i dati di una tabella in gruppi logici, in funzione di criteri specifici, come, ad esempio, una colonna che rappresenta una data o un valore numerico.
Questi gruppi sono chiamati, appunto, partizioni. Ogni partizione può essere gestita come un sottoinsieme separato dei dati.
Le partizioni sono utili perché consentono di elaborare grandi quantità di dati in modo più efficiente. Ad esempio, se si desidera eseguire un’analisi su un grande set di dati, le partizioni consentono di limitare il volume di dati da elaborare contemporaneamente, riducendo il tempo di esecuzione complessivo delle query.
Inoltre, le partizioni consentono di migliorare le prestazioni delle query in situazioni in cui vengono eseguite ricerche o aggregazioni frequenti su determinati gruppi di dati.
In generale, l’utilizzo delle partizioni è importante per migliorare l’efficienza e le prestazioni delle query, soprattutto quando si lavora con grandi set di dati.
Perché le partizioni sono importanti in AWS Athena
Come abbiamo visto, le partizioni permettono di organizzare i dati e, quindi, di rendere più efficienti le nostre query. Nel caso di Athena, tutto ciò impatta in maniera significativa anche sul costo stesso del servizio.
AWS Athena, per il servizio di Query SQL, ha un prezzo di 5,00 USD per TB di dati scansionati.
L’utilizzo di partizioni (e, quindi, studiare query che utilizzano tali partizioni) consente di limitare la mole di dati scansionati ai soli di interesse, riducendo, di fatto, tempi e costi.
Come organizzare i dati su AWS S3 per gestire automaticamente le partizioni di AWS Athena
Come abbiamo ampiamente specificato già nel primo articolo di questo topic, tutto dipende da come vengono organizzati i dati.
Quando si tratta di gestire le partizioni, ciò che veramente può fare la differenza è, soprattutto, il modo in cui andremo a salvare i dati su AWS S3.
Avevamo già visto quanto fosse importante strutturare i dati in maniera tale da suggerire ad Athena, in fase di costruzione di una tabella, in quali cartelle cercare.
AWS Athena riconoscerà come partizioni tutti i folder del tipo /chiave=valore/
Quindi, se, ad esempio, volessimo organizzare i nostri dati per data, potremmo immaginare una struttura delle cartelle su S3 più evoluta, passando da quella che avevamo visto:
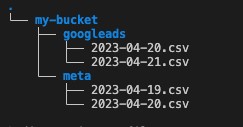
ad una di questo tipo:
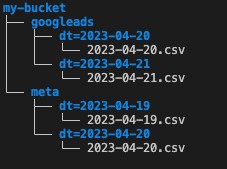
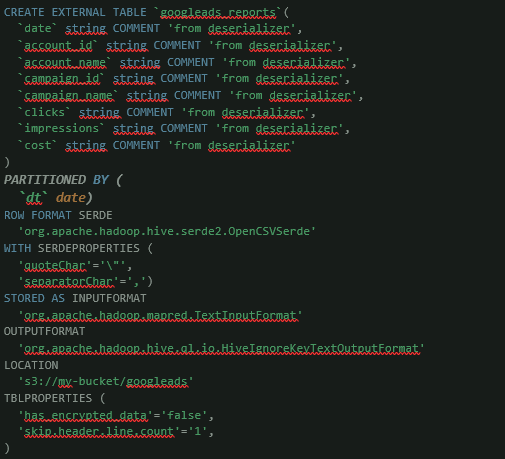
A questo punto, la nostra query per creare la tabella Athena dovrà necessariamente essere modificata per gestire la partizione. Quest’ultima verrà vista come una colonna extra della tabella stessa, utilizzando il costrutto “PARTITIONED BY“.
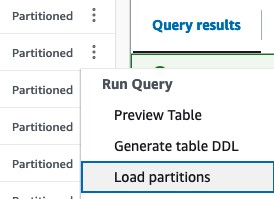
A questo punto, non resta che premere su Load Partitions ed attendere il processamento.
Performance Benchmark: Partizione vs Non Partizione
Chiudiamo con un’analisi delle performance, che ci consente di dimostrare in maniera inequivocabile le sostanziali differenze fra una query senza partizione o con partizione.
Abbiamo preso come riferimento dati strutturati simili a quelli dell’esempio precedente. Lo storage totale comprende due anni di dati, organizzati per giorno.
Abbiamo richiesto la somma dei dati per data, prendendo in considerazione sette giorni specifici, utilizzando, in un caso, la colonna ‘date’ e, nel secondo, caso la partizione ‘dt’: come potrete vedere, il risultato parla da sé.


Vuoi sapere come organizzare i dati su AWS S3? Vuoi ottimizzare le tue performance creando query che utilizzando le partizioni? Contattaci per maggiori informazioni!
Siamo anche su Facebook!
Vieni a trovarci, cliccando QUI!




